hybrid imagery, controlled generation, 3D, generative AI, compliance, photoreal production, methodology
Controlled Ai Hybrid Imagery
Pietro Fantoni · 18 June 2026

AI image generation is a buzzword, and like most buzzwords it describes an outcome while hiding the only thing that matters: control. Anyone can prompt a model and get something that looks plausible. Almost no one can make a model produce exactly what a brief requires, every time, in every region of the frame. That gap — between plausible and exact — is where most generated imagery falls apart the moment a real client looks closely.
By Pietro Fantoni, June 2026
The point is not that we use AI. The point is that we control it — and we can prove the seam is invisible.
We were asked to demonstrate the alternative. WE DO communication briefed us, as part of a pitch for BG BAU — the statutory accident insurer for the German construction industry — to produce two exemplary images. The constraint was specific and unforgiving: the images had to be photographic in quality, accurate down to the official tools and certified safety equipment of the construction trades, and produced without a real shoot. In a safety context, "approximately correct" equipment is worse than useless. A helmet that doesn't meet standard, a harness worn wrong, an invented tool — any of these turns a campaign image into a liability.
This is exactly the territory where uncontrolled generation fails. So we built a pipeline designed around control rather than around the technology.
3D is not the base layer. It is the control dial.
The common assumption is that a hybrid image starts with a 3D scene and adds AI on top. We worked the other way. We pushed generation as far as it would reliably go, and we added 3D only where it began to drift.
Where generation produced confusion or results we couldn't steer, we introduced basic 3D geometry to take control of generic shape, scale and perspective. Where a region had to be exactly right — the equipment that carries the safety message, the parts a client's compliance officer would scrutinise — we modelled it fully in 3D, mastered with photorealistic technique, and let nothing be left to chance.
So the amount of 3D in any region is a direct function of how much control that region demands. Loose background: mostly generation. Defining shape and pose: light 3D armature. Safety-critical detail: full 3D. The dial moves region by region across a single frame.
The process ran in stages. First, research — the exact official tools and equipment each scene required, established before any image existed. Then base 3D modelling of the two scenes, enough to fix poses, perspective and the elements that mattered. Then many iterations of controlled, region-by-region generation, hybridising the 3D base with prompting tight enough to govern each area of the image. Then a final polish, including generative work in Photoshop, to resolve the whole into a single photograph.
The compliance burden, in this model, moves to the front. On a real shoot, getting the safety gear right is a sourcing and supervision problem solved — or not — on the day, under time pressure, with talent who may wear it imperfectly. In our pipeline, that accuracy is resolved in research and locked into the model. Once it is correct, it is correct in every frame. And it remains fully reversible: we can adjust it during production and after, without reshooting anything.
We showed the client the seams — on purpose.
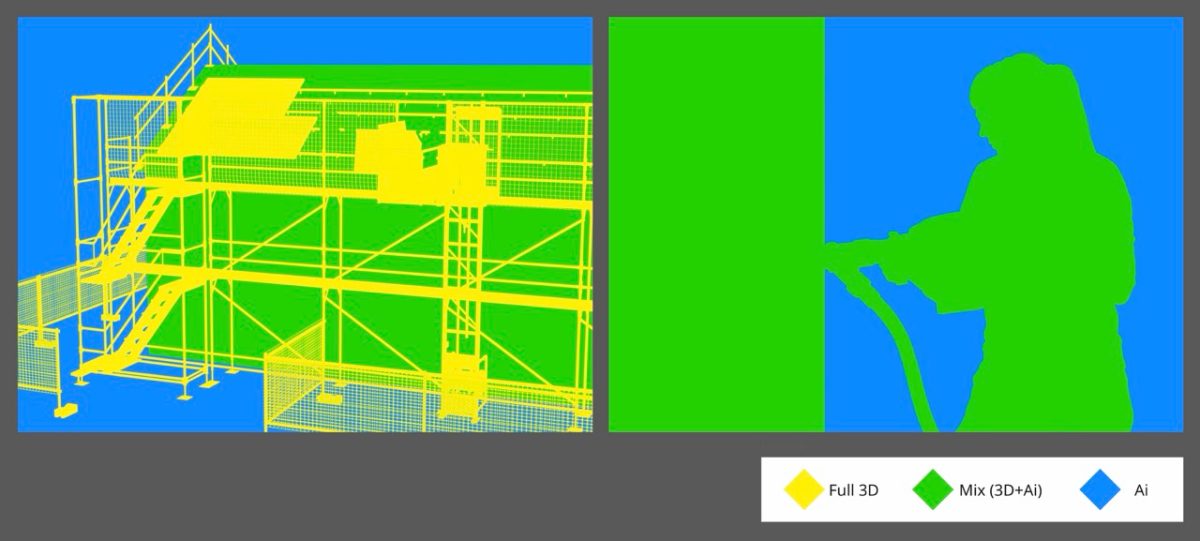
We delivered the two final images and, alongside them, a colour-coded version marking which areas were 3D, which were full generation, and which were hybrid.
In a competitive pitch, revealing your method can look like a risk. We treated it as proof. The overlay showed that each image was a mosaic of different techniques — and that the finished image was nonetheless a single, beautiful, photoreal frame ready for an advertising campaign. The seam between a fully modelled piece of equipment and a generated sky is invisible. That invisibility, demonstrated openly, is the whole argument. It also demonstrated scalability: a method you can see the structure of is a method you can repeat, scale and hand off.
The economics, under German conditions.
For full disclosure: producing these two pitch images took ten days in total. That was first-pass work — building the method while executing it. At full-scale production, with the pipeline established, we estimate the same output at under two days per image, one operator.
Set that against a real shoot for the same brief. A construction-safety scene — one of them aerial — means a photographer, a drone operator, an assistant; several talent dressed in correct, regulation-compliant workwear and PPE; a location, very likely an active or staged construction site, with the access, insurance and safety supervision that implies; roughly a day of preparation, a half to full day of shooting, a day of post-production. Location rental on top. Apply standard German labour and production costs to that crew and that schedule and the contrast is not marginal. One operator across two days does not compete with a half-day shoot — it replaces the entire apparatus around it.
And the apparatus is where the risk lives. Weather, site access, talent availability, gear that arrives wrong, the discovery in post that a critical detail was incorrect on the day. The hybrid pipeline removes most of those failure modes by resolving them before any pixel is committed.
There is a further advantage that outlasts the production itself. Because the image is built rather than captured, it stays flexible. Safety standards change — a new helmet certification, a revised harness specification, an updated regulation. A photograph would mean sourcing the new gear, re-staging the scene and shooting again. Here it means an edit: the affected region is regenerated to the new standard while the rest of the frame stays untouched. The image can be brought back into compliance whenever the requirements move, which gives the asset a far longer usable life than anything a camera produces.
How this could work for you.
The two images were first-pass work — the method built while it was being executed. The real leverage arrives one step further on, at campaign scale.
For a sustained programme, we train a dedicated generative model on your specific standards: your equipment, your compliance rules, your brand's visual language. Front-loaded compliance becomes systematised compliance — not "we got the equipment right this time," but a model that knows the rules and applies them across an entire campaign, image after image, with the same accuracy and the same reversibility. When a standard changes, the model changes with it, and every image that follows inherits the correction.
That is the difference between a clever one-off and an asset you own. A single photograph that was never photographed is a demonstration. A model that produces them on brief and on standard, frame after frame, and stays correct as the rules evolve, is a capability — one that belongs to you and gets cheaper, faster and more accurate the more you use it.
The part that matters.
So set the word "AI" aside. The deliverable was not generated imagery. It was two photographs that were never photographed, accurate to a regulated industry's standards, produced for a fraction of the cost and time of a shoot, with the method laid bare so anyone could see it held together. The technology is ordinary now. The control is not.

Pietro Fantoni · 18 June 2026
How We Work